javaScript面试题
javaScript
1.js 的基本类型有哪些?引用类型有哪些?null 和 undefined 的区别
基础数据类型
undefined、null、boolean、number、string
引用数据类型
function、object、array
null 和 undefined 的区别
提示
javaScript(ECMAScript 标准)里共有 5 种基本类型:Undefined, Null, Boolean, Number, String,和一种复杂类型 Object。可以看到 null 和 undefined 分属不同的类型,未初始化定义的值用 typeof 检测出来是"undefined"(字符串),而 null 值用 typeof 检测出来是"object"(字符串)。任何时候都不建议显式的设置一个变量为 undefined,但是如果保存对象的变量还没有真正保存对象,应该设置成 null。实际上,undefined 值是派生自 null 值的,ECMAScript 标准规定对二者进行相等性测试要返回 true
- undefined:表示变量声明但未初始化时的值
- null 表示准备用来保存对象,还没有真正保存对象的值。从逻辑角度看,null 值表示一个空对象指针
2.如何判断一个变量是 Array 类型?如何判断一个变量是 Number 类型
- 从原型入手,
Array.prototype.isPrototypeOf(obj)也可以从构造函数入手,obj instanceof Array根据对象的class属性(类属性),跨原型链调用toString()方法。Array.isArray()方法。 isNaN()是一个函数,用 isNaN 判断一个变量,返回一个Boolean值。若返回的值为 false,则为可以转换成数字类型;返回的值是 true,则不能转换成数字类型typeof()判断
3.Object 是引用类型嘛?引用类型和基本数据类型有什么区别?堆栈关系了解吗
Object 是引用类型。
基本类型
- 基本类型的值是不可变得
- 基本类型的比较是值的比较
- 基本类型的变量是存放在栈区的(栈区指内存里的栈内存)
引用类型
- 引用类型的值是可变的
- 引用类型的值是同时保存在栈内存和堆内存中的对象
引用类型与基本类型比较
| 基本类型:string,number,boolean,null,undefined | 引用类型:Function,Array,Object |
| 访问方式 | |
| 操作和保存在变量的实际的值 | 存在内存中,js 不许直接访问内存,操作的是对象的引用 |
| 存储的位置 | |
保存在栈区  | 引用存放在栈区,实际对象保存在堆区 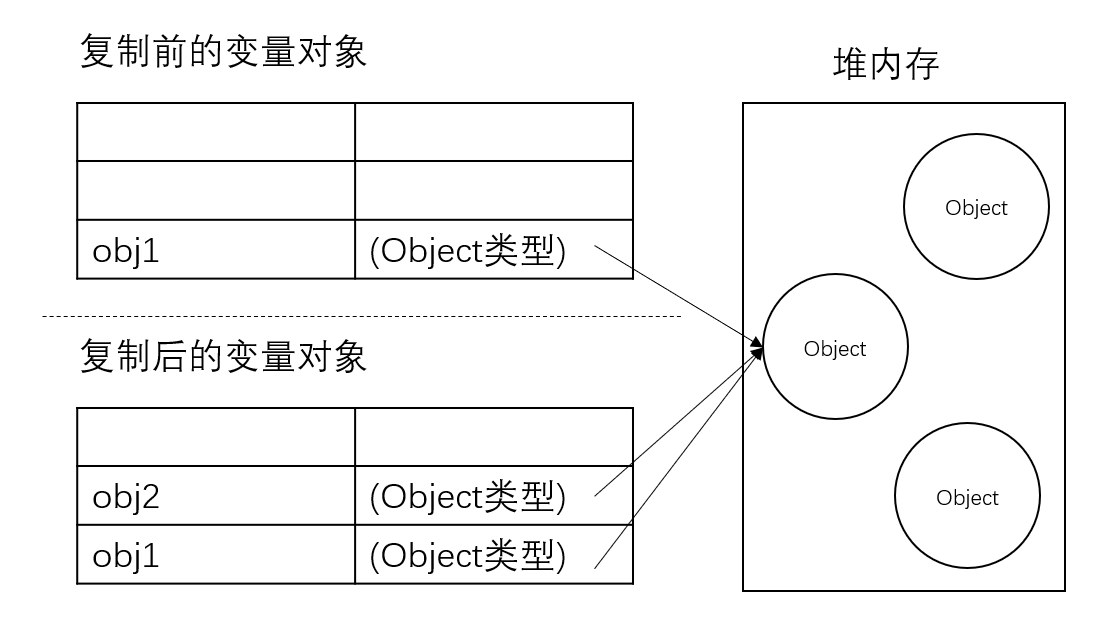 |
4.解释一下事件冒泡和事件捕获
- 事件冒泡:当你使用事件捕获时,父级元素先触发,子级元素后触发
- 事件捕获:当你使用事件冒泡时,子级元素先触发,父级元素后触发
5.事件委托,事件冒泡和捕获,如何阻止冒泡,如何阻止默认事件
事件委托:
var toolbar = document.querySelector('.toolbar')
toolbar.addEventListener('click', function (e) {
let button = e.target
if (!button.classList.contains('active')) {
button.classList.add('active')
} else {
button.classList.remove('active')
}
})
事件冒泡,就是元素自身的事件被触发后,如果父元素有相同的事件,如onclick事件,那么元素本身的触发状态就会传递,也就是冒到父元素,父元素的相同事件也会一级一级根据嵌套关系向外触发,直到document/window,冒泡过程结束
但是事件冒泡在某些应用场景产生一些问题,就是我们不需要触发的事件,由于冒泡的原因,也会运行。所以在这个时候要取消事件冒泡。阻止事件冒泡如下:
box.onmouseover = function (event) {
// 阻止冒泡
event = event || window.event
if (event && event.stopPropagation) {
event.stopPropagation()
} else {
event.cancelBubble = true
}
}
事件捕获,与事件冒泡相反,事件会从最外层开始发生,直到最具体的元素。事件捕获的概念下发生click事件的顺序应该是document -> html -> body -> div -> p。阻止事件冒泡如下:
// 阻止浏览器的默认行为
function stopDefault(e) {
// 阻止默认浏览器动作(W3C)
if (e && e.preventDefault) {
e.preventDefault()
} else {
window.event.returnValue = false
}
return false
}
6.对闭包的理解?什么时候构成闭包?闭包的实现方法?闭包的优缺点
提示
函数内部可以直接读取全局变量,但是在函数外部无法读取函数内部的局部变量。闭包就是能够读取其他函数内部变量的函数。内部函数对外部函数的变量有了引用关系——闭包就是这时产生的。每次对外部函数的调用,都会产生一次闭包
实现方法
- 给函数添加一些属性
- 声明一个变量,将一个函数当做值赋给变量
new一个对象,然后给对象添加属性和方法var obj={}就是声明一个空的对象
用处
它的最大用处有两个,一个是前面提到的可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中,不会在 f1 调用后被自动清除。
- 由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在 IE 中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
- 闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
7.this 有哪些使用场景?跟 JAVA 中的 this 有什么区别?如何改变 this 的指向
this 的使用场景
- 全局&调用普通函数,在全局环境中,
this永远指向window - 构造函数,如果函数作为构造函数使用,那么其中的
this就代表它即将new出来的对象 - 对象方法,如果函数作为对象的方法时,方法中的
this指向该对象。注意:若是在对象方法中定义函数,那么情况就不同了。函数a虽然是在b内部定义的,但它仍然属于一个普通函数,this仍指向window - 构造函数
prototype属性,即便是在整个原型链中,this 代表的也是当前对象的值 - 函数用
call、apply或者bind调用,当一个函数被call、apply或者bind调用时,this的值就取传入的对象的值 DOM event this,前六种情况其实可以总结为:this指向调用该方法的对象- 箭头函数中的
this,当使用箭头函数的时候,情况就有所不同了:箭头函数内部的this是词法作用域,由上下文确定
跟 JAVA 中的 this 有什么区别
java中this.value可以再本类中调用全局变量,也可以在构造器中用this()调用其他构造器,也可以用this表示当前对象 JavaScript 中this指的是这个函数所属的对象的值,当new一个函数时,这个 this 就会指向这个 new 出来的对象,apply()和call()可以改变一个函数中this指向的对象call和apply都可以改变this指向,不过call的第二个参数是散列分布,apply则可以是一个数组
8.call,apply,bind 有什么区别
call()和apply()的第一个参数相同,就是指定的对象。这个对象就是该函数的执行上下文。call()在第一个参数之后的 后续所有参数就是传入该函数的值。apply()只有两个参数,第一个是对象,第二个是数组,这个数组就是该函数的参数。bind()方法和前两者不同在于:bind()方法会返回执行上下文被改变的函数而不会立即执行,而前两者是直接执行该函数。他的参数和call()相同。
9.变量提升
javaScript 中,函数及变量的声明都将被提升到函数的最顶部 javaScript 中,变量可以在使用后声明,变量允许先使用再进行声明 javaScript 只有声明的变量会提升,初始化的不会
10.typeof 能得到哪些值
number、boolean、string、undefined、object、function
11.匿名函数典型用例
// 1.无参匿名函数
;(function () {
console.log('-----')
})()
// 2.携参匿名函数
;(function (params) {
console.log(params)
})({ id: '', name: '' })
12.创建对象有几种方式
- 通过{}创建对象
// 使用 {} 创建对象,等同于 new Object()
let obj = {}
obj.name = '测试'
obj.age = 20
obj.sayName = function () {
console.log(this.name)
}
console.log(obj.name + '-' + obj.age)
obj.sayName()
- new Object()
let obj = new Object() // 创建对象
obj.name = '测试'
obj.age = 20
obj.sayName = function () {
console.log(this.name)
}
obj.sayName()
console.log(obj instanceof Object) // true
console.log(typeof obj) // object
- 使用字面量
var person = { name: 'zhang', age: 20 }
提示
前面三种创建对象的方式存在 2 个问题: 1.代码冗余; 2.对象中的方法不能共享,每个对象中的方法都是独立的
- 工厂模式
工厂模式创建对象,减少重复代码,解决代码冗余问题,但不能共享对象
优点:【解决了代码重复问题】缺点:【调用的还是不同的方法】
// 定义工厂方法
function createObjectFactory(name) {
let obj = new Object()
obj.name = name
obj.sayName = function () {
console.log(this.name)
}
return obj
}
let a = createObjectFactory('zhang')
let b = createObjectFactory('liu')
console.log(a.sayName === b.sayName) // false
- 构造函数模式(
constructor)
构造函数:用 new 关键字来进行调用的函数称为构造函数,一般首字母要大写
// 创建构造函数
function Person(name) {
this.name = name
this.sayName = function () {
console.log(this.name)
}
}
var p1 = new Person('zhang')
var p2 = new Person('li')
p1.sayName()
p2.sayName()
console.log(p1.constructor === p2.constructor) //true
console.log(p1.constructor === Person) //true
console.log(typeof p1) //object
console.log(p1 instanceof Object) //true
console.log(p2 instanceof Object) //trueb
console.log(p1.sayName === p2.sayName) //false
- 原型模式(
prototype)
每个方法中都有一个原型(prototype),每个原型都有一个构造器(constructor),构造器又指向这个方法
function Animal() {}
Animal.prototype.name = 'animal'
Animal.prototype.sayName = function () {
alert(this.name)
}
var a1 = new Animal()
var a2 = new Animal()
a1.sayName()
console.log(a1.sayName === a2.sayName) //true
console.log(Animal.prototype.constructor) //function Animal(){}
console.log(Animal.prototype.constructor == Animal) //true
- 组合使用:构造模式+原型模式
结合了上面两种方式,解决了代码冗余,方法不能共享,引用类型改变值的问题
function Animal(name) {
this.name = name
this.friends = ['dog', 'cat']
}
Animal.prototype.sayName = function () {
console.log(this.name)
}
var a1 = new Animal('d')
var a2 = new Animal('c')
a1.friends.push('snake')
console.log(a1.friends) //[dog,cat,snake]
console.log(a2.friends) //[dog,cat]
13.document load和document DOMContentLoaded两个事件之前的区别
提示
区别:触发时机不一样,先触发 DOMContentLoaded事件,后触发 load事件
DOM 文档加载的步骤:
- 解析 HTML 结构
- 加载外部脚本和样式表文件
- 解析并执行脚本代码
- DOM 树构建完成,DOMContentLoaded 事件触发
- 加载图片等外部文件
- 页面加载完毕,load 事件触发
14.New 一个对象具体做了什么
使用关键字 new 创建新实例对象经过了以下几步
- 创建一个新对象,如:
var person = {} - 新对象的
_proto_属性执行构造函数的原型对象 - 将构造函数的作用域赋值给新对象(所以 this 对象指向新对象)
- 执行构造函数内部的代码,将书香添加给
person中的this对象 - 返回新对象
person
15.js 的参数使用什么方式进行传递的
基础类型的传递方式比较简单,是按照值传递进行的
let a = 1
function test(x) {
x = 10 // 并不会改变实参值
console.log(x)
}
test(a) // 10
console.log(a) // 1
复杂类型,传递的是地址
let a = {
count: 1
}
function test(x) {
x.count = 10
console.log(x)
}
test(a) // {count: 10}
console.log(a) // {count: 10}
16.javaScript 垃圾回收
js 中的内存分配和回收都是自动完成的,内存在不使用的时候会被垃圾回收器自动回收。如果不关注 js 内存管理问题,不了解 js 内存管理机制,同样容易造成内存泄露(内存无法被回收)的情况
内存的生命周期
js 环境中分配的内存,一般有如下生命周期:
- 内存分配:声明变量、函数、对象的时候,系统会自动为其分配内存
- 内存使用:即读写内存,也就是使用变量、函数等
- 内存回收:使用完毕,由来及回收自动回收不再使用的内存
内存分配
// 为变量分配内存
let a = 11
let b = 'code'
// 为对象分配内存
let person = {
name: 'code',
age: 20
}
// 为函数分配内存
function sum(a, b) {
return a + b
}
垃圾回收算法说明
所谓垃圾回收, 核心思想就是如何判断内存是否已经不再会被使用了, 如果是, 就视为垃圾, 释放掉
下面介绍两种常见的浏览器垃圾回收算法: 引用计数 和 标记清除法
引用计数
IE 采用的引用计数算法, 定义“内存不再使用”的标准很简单,就是看一个对象是否有指向它的引用。
如果没有任何变量指向它了,说明该对象已经不再需要了。
// 创建一个对象person, person指向一块内存空间, 该内存空间的引用数 +1
let person = {
age: 22,
name: 'ifcode'
}
let p = person // 两个变量指向一块内存空间, 该内存空间的引用数为 2
person = 1 // 原来的person对象被赋值为1,对象内存空间的引用数-1,
// 但因为p指向原person对象,还剩一个对于对象空间的引用, 所以对象它不会被回收
p = null // 原person对象已经没有引用,会被回收
由上面可以看出,引用计数算法是个简单有效的算法。
但它却存在一个致命的问题:循环引用。
如果两个对象相互引用,尽管他们已不再使用,垃圾回收器不会进行回收,导致内存泄露。
function cycle() {
let o1 = {}
let o2 = {}
o1.a = o2
o2.a = o1
return 'Cycle reference!'
}
cycle()
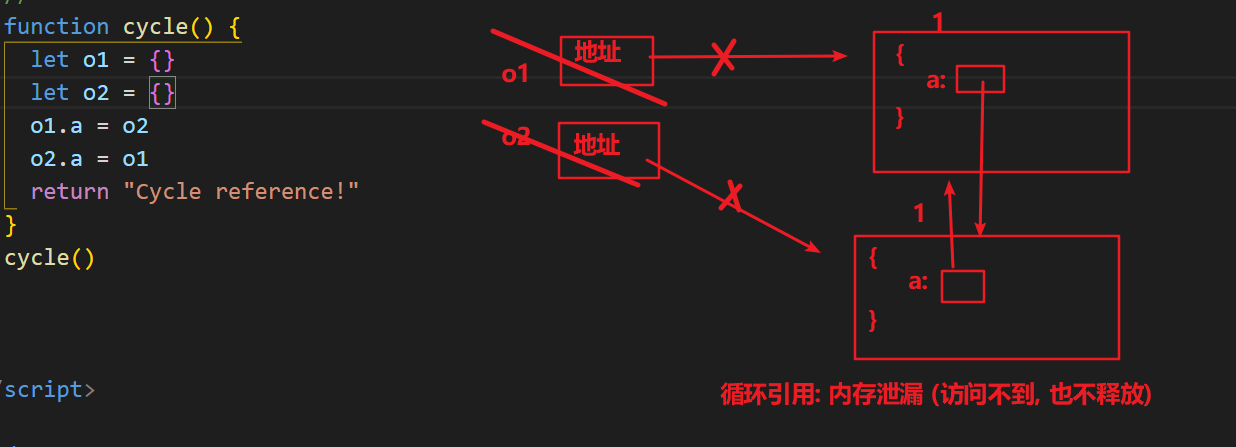
标记清除算法
现代的浏览器已经不再使用引用计数算法了。
现代浏览器通用的大多是基于标记清除算法的某些改进算法,总体思想都是一致的。
标记清除法:
标记清除算法将“不再使用的对象”定义为“无法达到的对象”。
简单来说,就是从根部(在 JS 中就是全局对象)出发定时扫描内存中的对象。
凡是能从根部到达的对象,都是还需要使用的。那些无法由根部出发触及到的对象被标记为不再使用,稍后进行回收。
从这个概念可以看出,无法触及的对象包含了没有引用的对象这个概念(没有任何引用的对象也是无法触及的对象)。
根据这个概念,上面的例子可以正确被垃圾回收处理了。
参考文章:JavaScript 内存管理
17.javaScript 作用域链的理解
JavaScript 在执⾏过程中会创建一个个的可执⾏上下⽂。 (每个函数执行都会创建这么一个可执行上下文)
每个可执⾏上下⽂的词法环境中包含了对外部词法环境的引⽤,可通过该引⽤来获取外部词法环境中的变量和声明等。
这些引⽤串联起来,⼀直指向全局的词法环境,形成一个链式结构,被称为作⽤域链。
简而言之: 函数内部 可以访问到 函数外部作用域的变量, 而外部函数还可以访问到全局作用域的变量,
这样的变量作用域访问的链式结构, 被称之为作用域链
let num = 1
function fn() {
let a = 100
function inner() {
console.log(a)
console.log(num)
}
inner()
}
fn()
下图为由多个可执行上下文组成的调用栈:
- 栈最底部为
全局可执行上下文 全局可执行上下文之上有多个函数可执行上下文- 每个可执行上下文中包含了指向外部其他可执行上下文的引用,直到
全局可执行上下文时它指向null
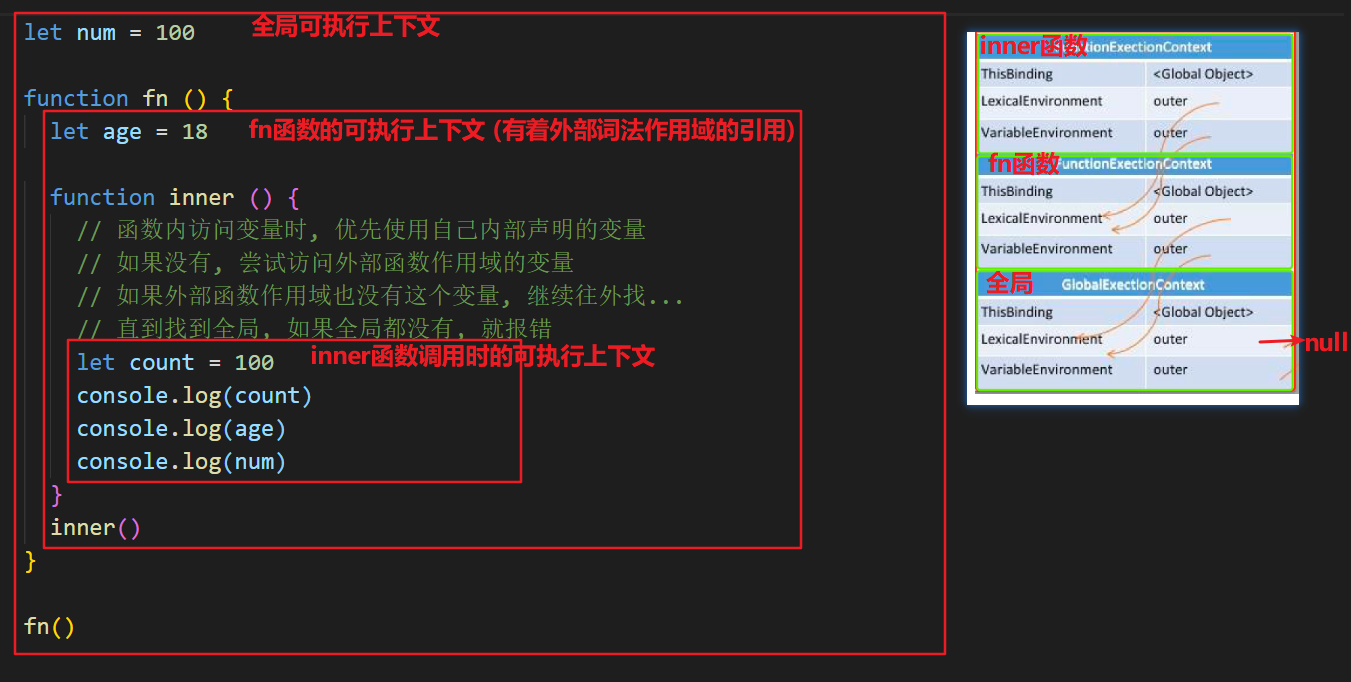
js 全局有全局可执行上下文, 每个函数调用时, 有着函数的可执行上下文, 会入 js 调用栈
每个可执行上下文, 都有者对于外部上下文词法作用域的引用, 外部上下文也有着对于再外部的上下文词法作用域的引用
=> 就形成了作用域链
18.闭包的理解
这个问题想考察的主要有两个方面:
- 对闭包的基本概念的理解
- 对闭包的作用的了解
什么是闭包?
MDN 的官方解释:
闭包是函数和声明该函数的词法环境的组合
更通俗一点的解释是:
内层函数, 引用外层函数上的变量, 就可以形成闭包
需求: 定义一个计数器方法, 每次执行一次函数, 就调用一次进行计数
let count = 0
function fn() {
count++
console.log('fn函数被调用了' + count + '次')
}
fn()
这样不好! count 定义成了全局变量, 太容易被别人修改了, 我们可以利用闭包解决
闭包实例:
function fn() {
let count = 0
function add() {
count++
console.log('fn函数被调用了' + count + '次')
}
return add
}
const addFn = fn()
addFn()
addFn()
addFn()
闭包的主要作用是什么?
在实际开发中,闭包最大的作用就是用来 变量私有。
下面再来看一个简单示例:
function Person() {
// 以 let 声明一个局部变量,而不是 this.name
// this.name = 'zs' => p.name
let name = 'hm_programmer' // 数据私有
this.getName = function () {
return name
}
this.setName = function (value) {
name = value
}
}
// new:
// 1. 创建一个新的对象
// 2. 让构造函数的this指向这个新对象
// 3. 执行构造函数
// 4. 返回实例
const p = new Person()
console.log(p.getName()) // hm_programmer
p.setName('Tom')
console.log(p.getName()) // Tom
p.name // 访问不到 name 变量:undefined
在此示例中,变量 name 只能通过 Person 的实例方法进行访问,外部不能直接通过实例进行访问,形成了一个私有变量。